Performance of Large Language Models in Interventional Cardiology: The ILLUMINATE Blinded Model-Comparison Study
© 2025 HMP Global. All Rights Reserved.
Any views and opinions expressed are those of the author(s) and/or participants and do not necessarily reflect the views, policy, or position of the Journal of Invasive Cardiology or HMP Global, their employees, and affiliates.
J INVASIVE CARDIOL 2025. doi:10.25270/jic/25.00104. Epub November 21, 2025.
Abstract
Objectives. Large language models (LLMs) have the potential to assist in complex decision making for interventional cardiology (IC). However, their comparative performance in providing clinical recommendations remains uncertain. In this blinded model‑comparison study, the authors evaluated and compared the quality of recommendations produced by 6 LLMs for complex IC cases.
Methods. Twenty detailed and complex clinical cases focusing on coronary artery disease (n=10) and structural heart disease (n=10) were developed. Six LLMs were tested: default ChatGPT (ChatGPTd), ChatGPT with European Society of Cardiology guidelines (ChatGPT-gl), ChatGPT with internet search enabled (ChatGPTi), Gemini (Google), Mistral 7B (Mistral AI), and Perplexity AI (Perplexity AI, Inc.). Only the ordering of anonymized outputs was randomized to ensure blinding. Five expert ICs independently assessed the anonymized and randomized responses using a 0 to 10 scale for appropriateness, accuracy, relevance, clarity, and clinical utility, generating a composite score. Statistical analysis was performed using a mixed linear model.
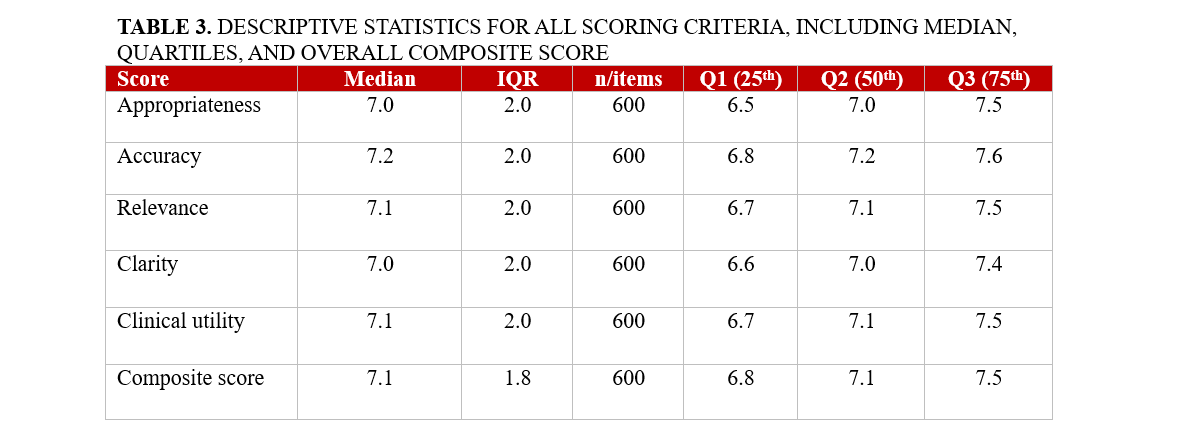
Results. Six hundred blinded evaluations (20 cases x 6 models x 5 raters) were analyzed, yielding an overall composite score of 7.1 (95% CI, 7.0-7.2). Performance significantly varied across LLMs (P < .001), with ChatGPTi (7.8 [7.5-8.0]) and ChatGPT-gl (7.7 [7.4-7.9]) outperforming others. ChatGPTd (6.9 [6.6-7.3]), Mistral 7B (7.0 [6.7-7.3]), and Perplexity AI (7.0 [6.7-7.3]) performed moderately, while Gemini had the lowest score (6.3 [6.0-6.7]). These differences were consistent across all scoring dimensions (P < .001). Case type did not affect LLM performance (P = .900).
Conclusions. LLMs show promise in IC decision making, but their performance remains suboptimal. Maximizing their potential requires systematic integration of web search capabilities and guideline-based knowledge retrieval.
Introduction
The rapid evolution of artificial intelligence (AI) presents new and original opportunities for enhancing clinical support, particularly in diagnostics, therapeutics, and decision-making processes. Current literature indicates that AI represents a valuable tool in clinical decision making, especially within fields like cardiology, where its ability to process complex datasets and real-time analysis can provide significant support to clinicians.1-7 Furthermore, recent research has demonstrated instances where large language models (LLMs) like ChatGPT (OpenAI) have not only matched, but even surpassed the diagnostic accuracy and completeness of responses provided by emergency room physicians and cardiologists in specific scenarios.8 For instance, ChatGPT-4o achieved 100% correct responses in evaluations of cardiovascular emergencies and provided faster, more comprehensive answers than its human counterparts, including cardiologists, in detailed scenarios.8 Similarly, in the context of patient education about coronary artery disease (CAD), ChatGPT delivered accurate and reproducible responses.8
However, several challenges remain, such as variability in AI outputs, errors in interpreting clinical queries, and issues with accuracy, which underscore the need for cautious and controlled implementation in medical practice.3,4,6,7,9 Integration into routine practice is challenging; moreover, effectiveness and accuracy remain active concerns given imperfect performance and occasional hallucinations.4,7,8,10 Although several studies have investigated the diagnostic performance of LLMs in general cardiology and emergency care, their effectiveness in guiding complex interventional cardiology (IC) decisions has not been systematically evaluated using blinded assessments by expert operators.4 Continued research and development are fundamental to fully take advantage of AI’s capabilities in real-world clinical settings.
In this study, we evaluated the performance of various AI-based LLMs in addressing 20 complex IC cases. Rather than comparing AI responses directly with those of cardiologists, the study focused on assessing the quality of AI-generated responses as judged by experienced ICs, using standardized criteria including appropriateness (guideline-concordance), accuracy (scientific correctness), relevance (focus on the case), clinical utility (actionability/decisiveness/feasibility within standard care), and clarity (organization, unambiguity). To mirror how clinicians encounter these tools, we purposively included both proprietary systems (eg, GPT-4 family, Gemini, Perplexity) and an open-source model (Mistral), reflecting different access models and update cadences. We also contrasted purely parametric chatbots with configurations that add retrieval (web browsing) and a guideline-anchored scaffold, allowing us to test whether structured access to contemporaneous European Society of Cardiology (ESC) guidance improves adherence, decisiveness, and clinical realism. Our objective was to analyze the strengths, limitations, and variability in performance among different AI models, focusing on their current capabilities and role in IC. This paper aims to provide insights into how AI can complement clinical decision making, identify key areas for improvement, and discuss the challenges and opportunities for future advancements in this rapidly evolving field.
Methods
Study design
The ILLUMINATE study is a prospective, blinded, model comparison study designed to evaluate the performance of various LLMs in dealing with complex IC scenarios. Randomization was applied only to the order of the anonymized model outputs presented to evaluators to ensure blinding. No participants were randomized to interventions; therefore, trial registration was not applicable. The objective was to compare the ability of these models to provide appropriate, accurate, and clinically useful responses based on predefined criteria.
Ethics
For this study, we used deidentified clinical vignettes with no protected health information or direct electronic health record text. No patient intervention or data linkage were involved. Per institutional policy, it qualified as non-human subject research, so formal institutional review board review was not required.
Clinical case selection
Twenty real-world IC clinical scenarios were selected and administered to 6 different LLMs. Cases were rewritten as deidentified vignettes prior to any LLM interaction. The cases were equally divided between CAD (n = 10) and structural heart disease (SHD) (n = 10). These cases reflected complex scenarios frequently encountered in IC, designed to assess the models’ ability to support clinical decision making (Supplemental Material).
Evaluated language models, model configuration, customization, and case administration
The 6 LLMs evaluated in the study were ChatGPTd (OpenAI, GPT‑4; default chat configuration; all models were queried between November and December 2024), ChatGPT‑gl (OpenAI, GPT‑4; fixed system prompt privileging ESC guidelines; all models were queried between November and December 2024), ChatGPTi (OpenAI, GPT‑4 with internet browsing enabled; all models were queried between November and December 2024), Gemini (Google, Gemini 1.5 Pro; all models were queried between November and December 2024), Perplexity AI (Perplexity AI, Inc., free tier; all models were queried between November and December 2024), and Mistral 7B (Mistral AI, open‑source; all models were queried between November and December 2024). The guideline corpus pre‑specified for reference included the ESC guidelines for the management of chronic coronary syndromes (2024), ESC guidelines for the management of acute coronary syndromes (2023), ESC/European Association for Cardio-Thoracic Surgery guidelines for the management of valvular heart disease (2021), ESC guidelines on myocardial revascularization (2018), ESC guidelines on atrial fibrillation (2024), and European Society of Gastrointestinal Endoscopy guidelines on endoscopic diagnosis and management of esophagogastric variceal hemorrhage (2022).
Web browsing was permitted to retrieve current guidance and primary literature. All models were provided with the same clinical cases and received identical text. Clinical cases were administered between November 1, 2024, and December 27, 2024. Where applicable, we recorded the model family, access tier, and month/year of access. Exact model names correspond to the providers’ public labels at the time of use. Each LLM was presented with the clinical case and asked the question: “How would you manage this scenario? What would you do?” If the provided responses were too general or lacked a definitive decision on the management of the clinical case, an additional prompt was administered: “What would you do in the end? Take a final decision.” This approach ensured that all models delivered conclusive recommendations about the management of the presented scenarios. Notably, in the specific scenario of clinical case administration to ChatGPT‑gl (guidelines privileged configuration), the corresponding guidelines’ .PDF files were uploaded along with an additional prompt: “Answer according to the European Society of Cardiology guidelines (ESC or others) uploaded for this case,” following the other standard commands administered in every case (“How would you manage this scenario? What would you do?”).
Evaluation criteria
The responses provided by the models were anonymized, randomized, and blindly assessed by 5 expert ICs. We did not include a comparator arm of human-generated recommendations. Because the ICs did not submit their own decisions on the vignettes, this was not a direct human-vs-LLM trial. The evaluation was conducted considering 5 specific criteria: (1) appropriateness, referring to compliance with clinical guidelines and best practices; (2) accuracy, meaning the scientific correctness and precision of the information provided; (3) relevance, measuring how pertinent the responses were to the presented clinical case; (4) clarity, referring to the comprehensibility and coherence of the response; and (5) clinical utility, assessing the practical value of the response in patient management. A composite score was calculated for each response with a maximum of 10 points. We did not pre-specify a binary threshold for correct vs incorrect answers. Instead, accuracy was scored on a 0 to 10 scale by 5 blinded ICs capture gradations from partially correct to fully guideline-concordant answers. Given clinical heterogeneity and acceptable alternative pathways, dichotomizing responses was deemed potentially misleading; accordingly, primary analyses used the continuous scores (accuracy and the composite index).
Randomization and anonymization process
The responses generated by the LLMs were collected and anonymized to prevent evaluation bias. A randomization of the answers was performed using a basic data handling software (Microsoft Excel) to ensure an impartial assessment by the evaluators. When the models quoted external sources or references to guidelines, those were removed from the exported text before grading to preserve blinding. To avoid model identification by style, we removed explicit citations and any provider identifiers from all outputs before randomization.
Statistical analysis
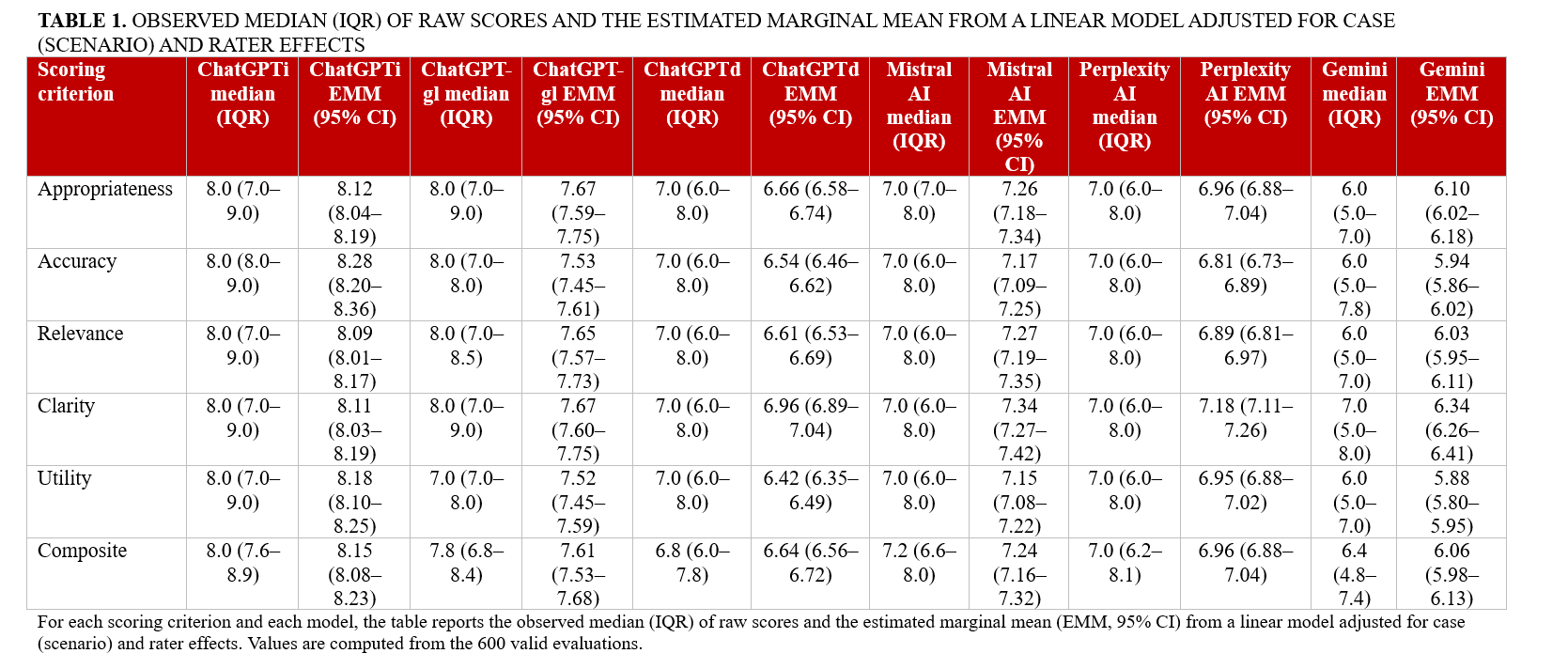
Analyses were performed post-collection in March 2025 using Python (Python Software Foundation) and R (The R Project for Statistical Computing). For descriptive purposes, evaluation scores for each domain and the composite score were reported as medians with IQRs. Inter-rater agreement for composite scores was quantified using a 2-way random-effects, absolute-agreement, single-measure intraclass correlation coefficient [ICC (2,1)] on complete-case evaluations, and agreement in case rankings across evaluators was assessed with Kendall’s coefficient of concordance (W). For inferential comparisons of performance across LLMs, we fitted linear mixed-effects models with random intercepts for case and rater and obtained model-specific estimated marginal means (EMMs) with 95% CIs. Between-model pairwise contrasts were adjusted for multiple testing using false discovery rate (FDR) control within each evaluation criterion. In addition to the composite score analyses, we summarized criterion-level performance for each model. For every scoring criterion (appropriateness, accuracy, relevance, clarity, and clinical utility) and each LLM, we reported both the observed median (interquartile range [IQR]) of raw scores and the corresponding EMMs (95% CI) derived from the same mixed-effects framework. These domain-specific results are presented in Table 1 to highlight the strengths and weaknesses of individual models across evaluation dimensions.
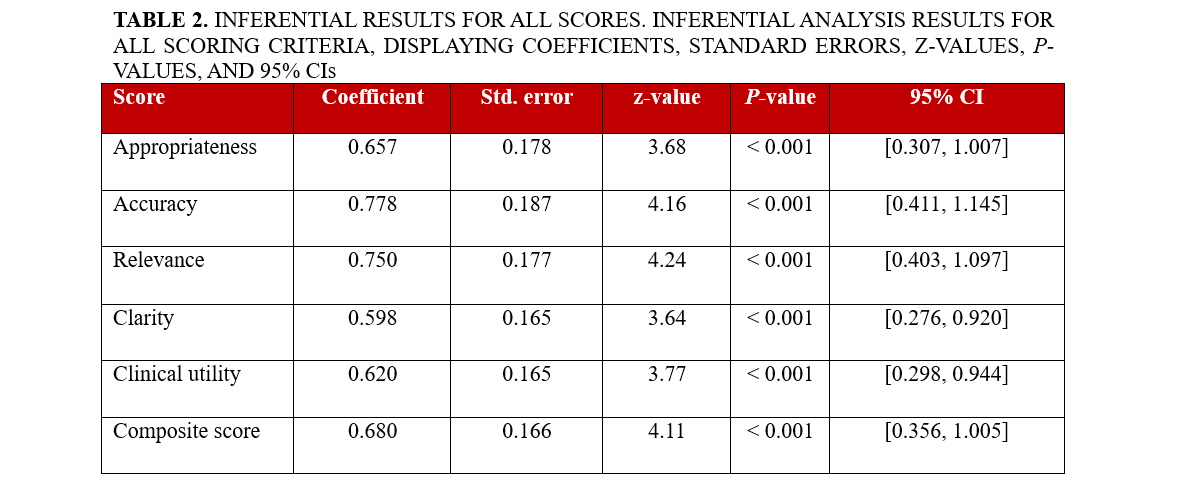
Associations between accuracy and clinical utility were assessed primarily with Spearman’s rank correlation coefficient (ρ, 95% CI), with Pearson’s r and partial correlations (after residualizing for case and rater effects) reported as supportive analyses. A 2-sided P-value of less than 0.05 was considered statistically significant. Additionally, to quantify how each evaluation domain related to perceived clinical utility, we fitted separate linear mixed-effects models with clinical utility as the dependent variable, the domain score as fixed effect, and random intercepts for case and rater; the resulting coefficients, standard errors, z-values, P-values, and 95% CIs are reported in Table 2.
Results
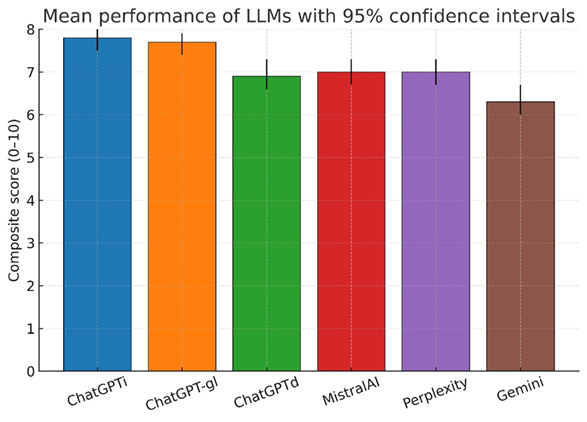
We analyzed 600 blinded evaluations (20 cases × 6 models × 5 raters), corresponding to 120 case-model composite scores. The overall composite score for AI performance in complex IC cases was 7.1 (95% CI, 7.0-7.2). The distribution of domain-specific scores and composite scores is summarized in Table 3. However, significant differences were observed among the models (P < .001). ChatGPTi achieved the highest performance with a composite score of 7.8 (95% CI: 7.5-8.0), followed closely by ChatGPT-gl, which scored 7.7 (95% CI: 7.4-7.9). ChatGPTd performed notably worse, achieving a score of only 6.9 (95% CI: 6.6-7.3). Similarly, Mistral 7B and Perplexity AI both recorded a composite score of 7.0 (95% CI, 6.7-7.3). The lowest-performing model was Gemini, which scored 6.3 (95% CI, 6.0-6.7) (Figure 1; Table 4).
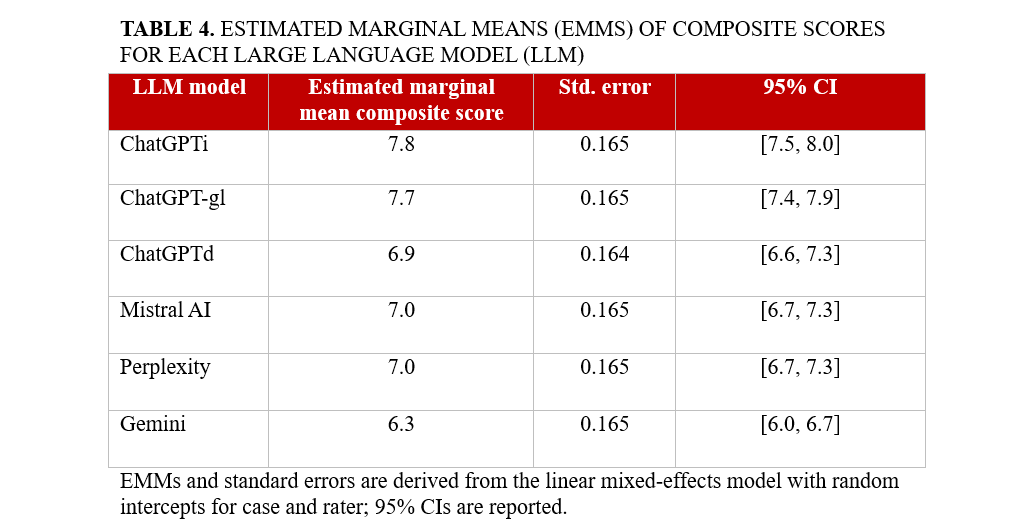
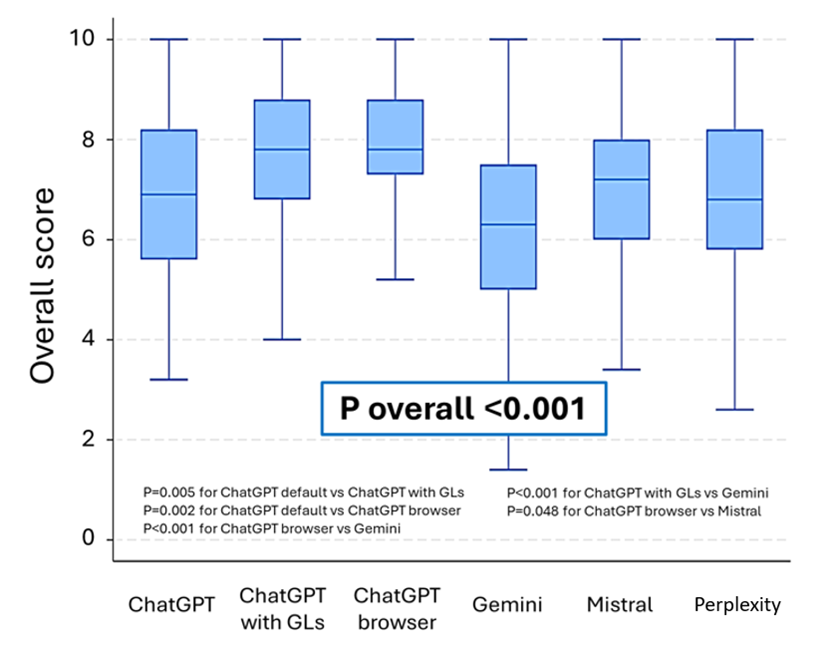
All 5 evaluation criteria (appropriateness, accuracy, relevance, clarity, and clinical utility) followed a similar trend, with ChatGPTi and ChatGPT-gl performing better than the other models (all P < .001). Models equipped with integrated guideline access and internet search capabilities generated more contextually relevant and accurate responses. Criterion-level performance by model is detailed in Table 1. ChatGPTi and ChatGPT-gl consistently achieved the highest median and EMM values across all 5 domains, particularly for appropriateness, accuracy, and clinical utility, confirming their overall superiority across evaluation criteria. Mistral 7B and Perplexity AI showed intermediate performance with generally acceptable scores, whereas Gemini systematically underperformed with lower appropriateness, accuracy, and clarity scores. These domain-specific patterns are fully consistent with the composite score rankings reported in Table 4.
We flagged an additional prompt when a model’s initial output lacked a firm, actionable decision. Extra nudges were frequent with non-scaffolded models—ChatGPTd 15/20 (75%), Gemini 18/20 (90%), Perplexity AI 12/20 (60%), Mistral 7B 13/20 (65%)—and less common with scaffolded variants—ChatGPT-gl 4/20 (20%), ChatGPTi 6/20 (30%). This pattern indicates that guideline/retrieval scaffolding improves first-pass completeness by reducing the need for follow-ups. No significant performance differences were observed between cases related to CAD and those involving SHD (P = .900), suggesting that model performance was consistent across the different domains of IC evaluated in this study.
To test whether clinical utility reflected an independent judgment or was driven by accuracy, we quantified their association across all evaluations (N = 600). Accuracy was strongly correlated with clinical utility (Pearson r = 0.860; 95% CI, 0.838-0.880). This relationship persisted, though attenuated, after controlling for evaluator and model via fixed-effects residualization (partial r = 0.796; 95% CI, 0.764-0.824). Rank-based analyses were consistent (Spearman ρ = 0.826; partial ρ = 0.767; both P < .001). Thus, while clinical utility is not redundant with accuracy, greater accuracy substantially increases perceived clinical usefulness.
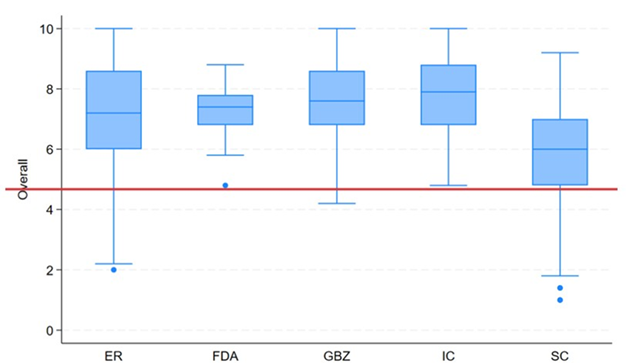
To contextualize between-model differences, we examined how cardiologist evaluators distributed scores across the same items. Figure 2 shows, for each evaluator, the distribution of composite scores (0-10) across complete subjects (ie, case × model combinations with all 5 ratings). Inter-rater reliability for the composite score—estimated with a 2-way random-effects, absolute-agreement, single-measure intraclass correlation—was ICC (2,1) = 0.208 (95% CI, 0.183-0.361), indicating poor absolute agreement between individual raters. Rank concordance across evaluators was Kendall’s W equal to 0.436, P-value of 9.37×10⁻¹², consistent with moderate concordance of ranks. Item-level and composite ratings are reported as median (IQR). Model-level performance panels show EMMs (95% CI) from the mixed model (Figure 3).
Discussion
Our findings extend a rapidly growing literature on LLMs in cardiovascular medicine. Prior studies have shown that LLMs can assist heart-team deliberations in severe aortic stenosis, often aligning with expert consensus while shortening decision cycles.11 Others have documented that off-the-shelf models achieve variable but non-trivial performance on interventional certification items2 and cardiology board-style multiple-choice questions.6 In acute care and general cardiology contexts, LLMs have sometimes matched or exceeded clinicians for specific tasks such as structured diagnostic reasoning or patient-facing education, though results are heterogeneous.2,4,6 Parallel methodological work has emphasized that guideline-aware prompting and retrieval-augmented generation can substantially improve adherence to evidence-based recommendations and that clinical utility hinges on transparency, calibration, and guardrails.12-16
This study provides a global assessment of the use of LLMs in decision making in IC. Through a systematic evaluation of 6 LLMs across multiple real-world cases, we identified key strengths and limitations in their capacity to deliver clinically relevant guidance. The findings of this study underscore the potential of AI-assisted decision making in IC, simultaneously highlighting the important variability in performance among different models. A critical finding of our study is that LLMs with access to external data sources, such as internet-enabled search capabilities (ChatGPTi) or preloaded clinical guidelines (ChatGPT-gl), significantly outperformed their counterparts (Figure 1 and Table 4). This suggests that incorporating real-time access to evidence-based guidelines and literature enhances the reliability and applicability of AI-generated recommendations. Conversely, LLMs operating without external data integration, such as Gemini and ChatGPTd, demonstrated lower performance, emphasizing the limitations of static knowledge models in a rapidly evolving field like IC.
IC moves quickly, with frequent updates to antithrombotic therapy, device indications, and imaging-guided optimization. Models that rely on fixed training data and lack targeted retrieval tend to drift from current evidence and may default to generic or incorrect recommendations. By contrast, approaches that surface the latest guidance and explicitly anchor reasoning to class of recommendation and level of evidence statements reduce ambiguity and improve usability. In our evaluation, the web-enabled (ChatGPTi) and guideline-structured (ChatGPT-gl) configurations consistently outperformed the default, purely parametric versions across all 5 domains, with differences that were both statistically and practically significant.
While ChatGPTi and ChatGPT-gl performed well, none of the evaluated models achieved perfect scores, indicating room for improvement and progress to be made. The need for additional prompting to obtain definitive recommendations also highlights current limitations in AI autonomy (inter-evaluator variability illustrated in Figure 2). Designing prompt frameworks that demand a final, accountable decision tied to guideline classes/levels and key contraindications may therefore be a practical lever for improving clinical utility. Moreover, our study focused exclusively on AI-generated recommendations rather than a direct comparison with human decision making, leaving open the question of how LLMs compare to expert cardiologists in real-world patient management.
Limitations
Despite its design, our study has several limitations. We took into consideration a small sample of 20 clinical scenarios, which may limit the generalizability of the findings to broader clinical practice. The AI models’ responses could also be influenced by their training data, potentially leading to inconsistent outputs. Extensive web search capabilities and careful adherence to guidelines are also not systematically or explicitly implemented. Furthermore, it is worth considering that the rapid evolution of AI technology may result in findings that quickly become outdated, necessitating continuous evaluation.
Conclusions
The findings of the ILLUMINATE study highlight the significant potential of LLMs in supporting complex decision making in IC. Our analysis of 6 different AI-based models demonstrated notable variability in their performance, with ChatGPT versions that integrate internet search capabilities and ESC guidelines outperforming other models. These enhanced versions provided more appropriate and clinically useful responses compared with their counterparts that lack external information access. Ultimately, while LLMs show potential to help and to support ICs in managing complex cases, their integration into clinical practice is still far from perfect and requires further improvement. Future research should focus on optimizing AI performance through enhanced contextual understanding, real-time data integration, and systematic adherence to medical guidelines. Additionally, regulatory oversight and clinician involvement will be critical in the process of ensuring a safe and effective AI-assisted decision making in cardiology.
These findings may have practical implications for the integration of AI tools into the workflow of ICs. LLMs equipped with real-time internet access and guideline-based databases may be incorporated into clinical decision-support platforms to assist physicians during case planning and periprocedural strategy selection. As AI technology continues to evolve, future development should focus on increasing clinical contextual awareness, minimizing hallucinations, and incorporating regulatory safeguards to ensure patient safety. Prospective studies are needed to validate the real-world impact of LLMs on clinical outcomes and workflow efficiency in the catheterization laboratory.
Affiliations and Disclosures
Attilio Lauretti, MD1-9; Iginio Colaiori, MD1; Simone Calcagno, MD2; Enrico Romagnoli, MD3; Fabrizio D’Ascenzo, MD4,5; Antonio Di Matteo, MD1; Francesco Gemelli, MD1; Gaetano Pero, MD1; Marco Bernardi, MD1-6; Luigi Spadafora, MD1-6; Antonio Esposito, MD8; Marco Borgi, MD1; Giuseppe Biondi-Zoccai, MD, MStat6,7; Francesco Versaci, MD1
From the 1Division of Cardiology, Santa Maria Goretti Hospital, Latina, Italy; 2Cardiology Unit, Department of Emergency and Admission, San Paolo Hospital, Civitavecchia, Italy; 3Department of Cardiovascular Sciences, Fondazione Policlinico Agostino Gemelli IRCCS, Rome, Italy; 4Division of Cardiology, Cardiovascular and Thoracic Department, Città della Salute e della Scienza, Turin, Italy; 5Division of Cardiology, Department of Medical Sciences, University of Turin, Italy; 6Department of Medical-Surgical Sciences and Biotechnologies, Sapienza University of Rome, Latina, Italy; 7Maria Cecilia Hospital, GVM Care & Research, Cotignola, Italy; 8ICOT Marco Pasquali Institute, Cardiovascular Department Latina, Italy; 9Department of Clinical and Molecular Medicine, Sapienza University of Rome, Rome, Italy.
Disclosures: Dr Biondi-Zoccai has consulted for Abiomed, Advanced Nanotherapies, Aleph, Amarin, Balmed, Cardionovum, Crannmedical, Endocore Lab, Eukon, Guidotti, Innovheart, Meditrial, Menarini, Microport, Opsens Medical, Terumo, and Translumina, outside the present work. The remaining authors report no financial relationships or conflicts of interest regarding the content herein.
Address for correspondence: Attilio Lauretti, MD, Division of Cardiology, Santa Maria Goretti Hospital, Via Lucia Scaravelli, 04100 Latina, Italy. Email: attilio.lauretti@uniroma1.it; Instagram: @attiliolauretti
References
- Itelman E, Witberg G, Kornowski R. AI-assisted clinical decision making in interventional cardiology: the potential of commercially available large language models. JACC Cardiovasc Interv. 2024;17(15):1858-1860. doi:10.1016/j.jcin.2024.06.013
- Alexandrou M, Mahtani AU, Rempakos A, et al. Performance of ChatGPT on ACC/SCAI interventional cardiology certification simulation exam. JACC Cardiovasc Interv. 2024;17(10):1292-1293. doi:10.1016/j.jcin.2024.03.012
- Geneş M, Çelik M. Assessment of ChatGPT's compliance with ESC-acute coronary syndrome management guidelines at 30-day intervals. Life (Basel). 2024;14(10):1235. doi:10.3390/life14101235
- Goh E, Gallo R, Hom J, et al. Large language model influence on diagnostic reasoning: a randomized clinical trial. JAMA Netw Open. 2024;7(10):e2440969. doi:10.1001/jamanetworkopen.2024.40969
- Gurbuz DC, Varis E. Is ChatGPT knowledgeable of acute coronary syndromes and pertinent European Society of Cardiology Guidelines? Minerva Cardiol Angiol. 2024;72(3):299-303. doi:10.23736/S2724-5683.24.06517-7
- Huwiler J, Oechslin L, Biaggi P, Tanner FC, Wyss CA. Experimental assessment of the performance of artificial intelligence in solving multiple-choice board exams in cardiology. Swiss Med Wkly. 2024;154:3547. doi:10.57187/s.3547
- Madaudo C, Parlati ALM, Di Lisi D, et al. Artificial intelligence in cardiology: a peek at the future and the role of ChatGPT in cardiology practice. J Cardiovasc Med (Hagerstown). 2024;25(11):766-771. doi:10.2459/JCM.0000000000001664
- Geneş M, Deveci B. A clinical evaluation of cardiovascular emergencies: a comparison of responses from ChatGPT, emergency physicians, and cardiologists. Diagnostics (Basel). 2024;14(23):2731. doi:10.3390/diagnostics14232731
- Sarraju A, Ouyang D, Itchhaporia D. The opportunities and challenges of large language models in cardiology. JACC Adv. 2023;2(7):100438. doi:10.1016/j.jacadv.2023.100438
- Pay L, Yumurtaş AÇ, Çetin T, Çınar T, Hayıroğlu Mİ. Comparative evaluation of Chatbot responses on coronary artery disease. Turk Kardiyol Dern Ars. 2025;53(1):35-43. doi:10.5543/tkda.2024.78131
- Salihu A, Meier D, Noirclerc N, et al. A study of ChatGPT in facilitating heart team decisions on severe aortic stenosis. EuroIntervention. 2024;20(8):e496-e503. doi:10.4244/EIJ-D-23-00643
- Wu X, Huang Y, He Q. A large language model improves clinicians' diagnostic performance in complex critical illness cases. Crit Care. 2025;29(1):230. doi:10.1186/s13054-025-05468-7
- Novak A, Rode F, Lisičić A, et al. The pulse of artificial intelligence in cardiology: a comprehensive evaluation of state-of-the-art large language models for potential use in clinical cardiology. medRxiv. Preprint posted August 8, 2023. doi:10.1101/2023.08.08.23293689
- Pierri MD, Galeazzi M, D’Alessio S, et al. Evaluating large language models in cardiology: a comparative study of ChatGPT, Claude, and Gemini. Hearts. 2025;6(3):19. doi:10.3390/hearts6030019
- Masanneck L, Meuth SG, Pawlitzki M. Evaluating base and retrieval augmented LLMs with document or online support for evidence based neurology. NPJ Digit Med. 2025;8(1):137. doi:10.1038/s41746-025-01536-y
- Ozmen BB, Mathur P. Evidence-based artificial intelligence: implementing retrieval-augmented generation models to enhance clinical decision support in plastic surgery. J Plast Reconstr Aesthet Surg. 2025;104:414-416. doi:10.1016/j.bjps.2025.03.053